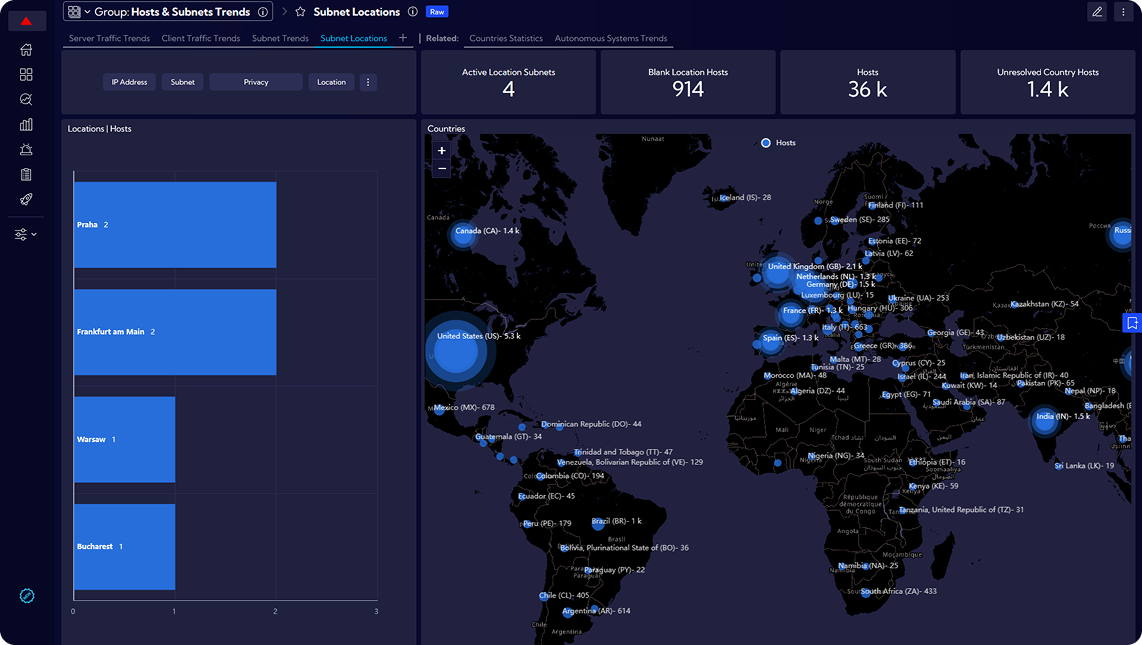
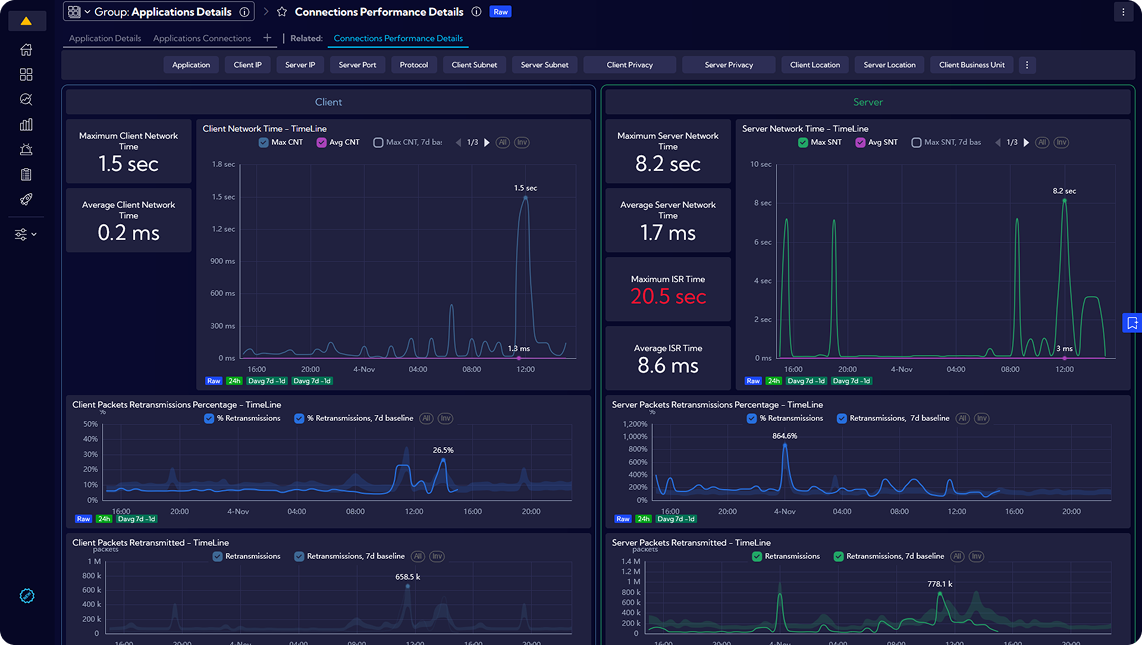
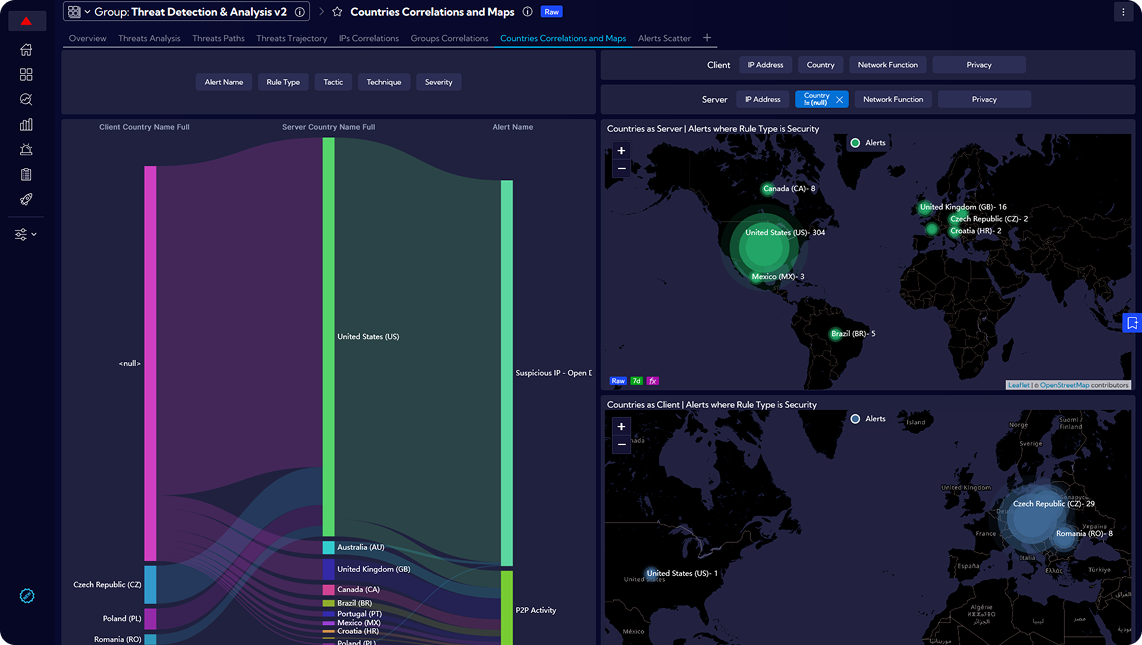
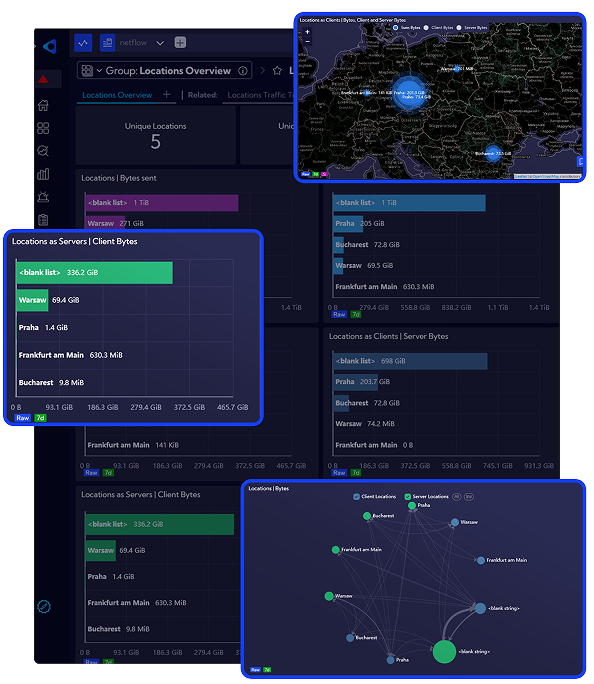
Sycope to polska firma technologiczna specjalizująca się w rozwiązaniach do monitorowania infrastruktury IT i cyberbezpieczeństwa, wspierająca organizacje z sektora finansowego, medycznego, telekomunikacyjnego i publicznego na całym świecie w budowaniu bezpiecznych i wydajnych sieci. Jej głównym produktem jest platforma Sycope do monitorowania sieci i analizy ruchu w czasie rzeczywistym. Rozwiązanie oparte na zaawansowanej analizie flow (NetFlow, sFlow, IPFIX) pozwala zespołom IT i bezpieczeństwa szybko wykrywać zagrożenia, eliminować wąskie gardła, zapewniać zgodność z politykami oraz optymalizować wydajność środowiska. Sycope umożliwia bieżące monitorowanie wydajności sieci, skuteczne wykrywanie ataków – takich jak DDoS, skanowanie portów, eksfiltracja danych czy lateral movement – oraz sprawne reagowanie na incydenty dzięki rozbudowanym mechanizmom alertowania i raportowania wspierającym pracę zespołów SOC i NOC. Przejrzyste dashboardy i intuicyjny interfejs przyspieszają analizę oraz identyfikację przyczyn problemów, a integracja z istniejącymi systemami IT poprzez REST API i zewnętrzne źródła threat intelligence pozwala łatwo włączyć platformę do obecnego ekosystemu organizacji.